This is a preliminary list of results from a research project is being compiled into full paper on the subject.
The full paper, in it's academic form is now available on arxiv.
WIGI is the Wikipedia Gender Inequality Index, a project whose purpose is to attempt to gain insight into the gender gap through understanding which humans are represented in Wikipedia. Professor Piotr Konieczny, and myself thought that, whereas some gender gap research focuses on the editors of Wikipedia directly, we would view the content and metadata of articles as a proxy measure for those editing. Although the notion of analysing Wikipedia content seems quite old, I believe the advent of Wikidata allows us a new range of ambitious questions to be asked.
We use Wikidata, the new semantic database that feeds Wikipedia. By inspecting it's weekly data dumps, we are able to inspect all the semantic properties associated with every Wikipedia page in any language, all at once. In this case we focus on any article that is about a person, and their any data recorded for the properties gender, date of birth, date of death, place of birth, citizenship, and ethnic group (example). We do this courtesy of an excellent tool known as the Wikidata Toolkit.
We compare the found data to historical census data and the World Economic Forum's Gender Gap Index.
For other computations we also supplement the original data with with aggregation maps to make cultures from place of birth, citizenship, and ethnic group, by using Mechanical Turk.
This project has been conducted in an Open Notebook Science way, where we have been posting our results and receiving feedback as we work. You can chat with us on-wiki, or on-github where all the code and data needed to reproduce this research is available.
Let's begin:
As of October 14 2014 we inspected a total of 2,561,999 or about 2.5 million "human" items, that is any Wikidata item with the property "instance of: Q5 (human)".
On each of those items we look for the following additional properties and found them no the following number of items.
\% of total Items with property
------------------------------------------------------------------------------------- ------------- ---------------------
[ethnic group](http://www.wikidata.org/wiki/Property:P172) 0.30 7,772
country* 23.47 601,361
[place of birth](http://www.wikidata.org/wiki/Property:P19) 23.93 613,092
[date of death](http://www.wikidata.org/wiki/Property:P570) 28.79 737,522
[citizenship](http://www.wikidata.org/wiki/Property:P27) 41.44 1,061,634
culture** 45.20 1,158,086
[date of birth](http://www.wikidata.org/wiki/Property:P569) 57.92 1,484,003
[gender](https://www.wikidata.org/wiki/Property:P21) 89.40 2,290,433
[at least one site link](https://www.wikidata.org/wiki/Wikidata:Glossary#Sitelinks) 99.05 2,537,545
a "Q" ID 100.00 2,561,999
*country is determined by seeing if the place of birth is a country, or if it is a city, see if the city has a country property
**culture is determined by using translating ethnic group, place of birth, and citizenship into 1 of 9 world cultures as per Inglehart-Welzel map of the world with Mechanical Turk. Then we take the consensus of the three aggregated variables. (Actually there were no disagreements between the three variables.) All aggregation maps are available for inspection on github.
Now the first derived and naive statistic of interest - the total gender breakdown. As we've seen above 10.3% is of unknown gender, otherwise we encounter 75.7% male, 13.9% female, and <.01% nonbinary which is perhaps better described as 152 cases.
We want some sanity checking that the data from Wikidata reflects the world at large. To do this we compared our total population per year, calculated by date of birth, versus the world population.
Comparing the Wikidata data to historical census data we find a high significant correlation in total population - Pearson correlation coefficent = .983 with p<0.01. This lends some credence to the notion that this dataset reflects the world at large. (By the way the historical data trends backwards to 10,000 BCE, but the earliest date of birth in Wikidata is about 4,000 BCE.)
These graphs show the absolute volume of items by date of birth and death by gender, and over all time, and 1800 onwards.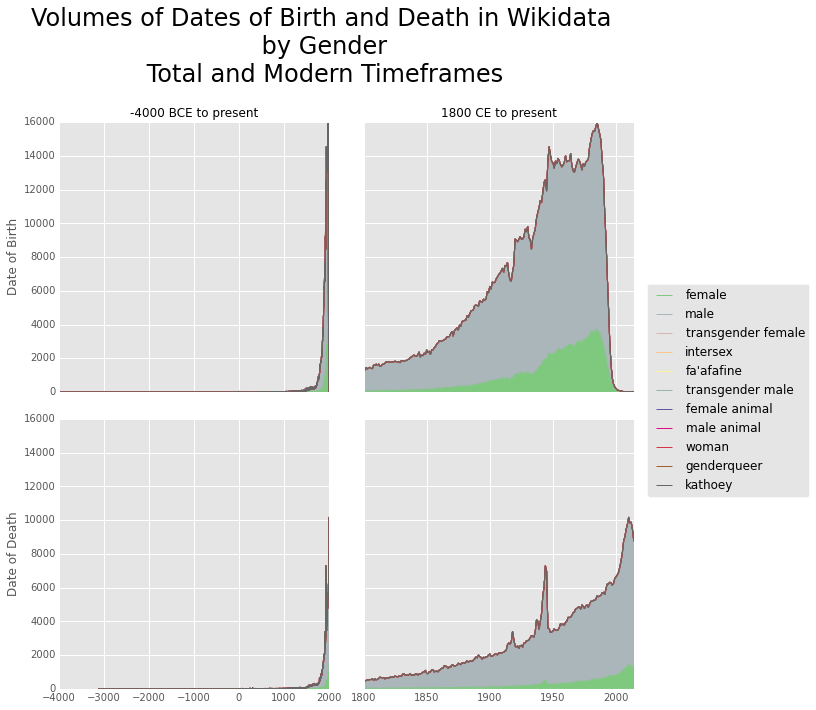
This first visualization of the gender gap shows how Wikipedia's retroactive focus on history has been consistent in it's bias in representing females. It's also generally quite a smooth curve save for some noticable spikes around World War I and II.
It's intriguing to contemplate how we might expect date of birth and death to be related. If they were equally well recorded - and barring extreme events like wars - the death curve would look like a right-shifted birth curve. However we see empirically that is not true. At all times the death curve remains absolutely smaller than birth, by a factor of about two-thirds. So we can see a bias in recording the date of birth more often than than date of death.
The indication of visual skew in gender prodded me to look at how the ratio of male female and nonbinary genders develop over time.
Note: From here I aggregate the nonbinary genders into a single class not for philosophical reasons of them, but for the ease of visualising the more dimensions they represent. I consider it import to be descriptive about what is found in the data, and to not to lose any perspective because of personal assumptions about gender. If you think there are better ways to describe this data, I would be glad to here from you.
We adjust our viewing window here to start at 1400CE here because the data is too sparse to provide meaningful visual data.
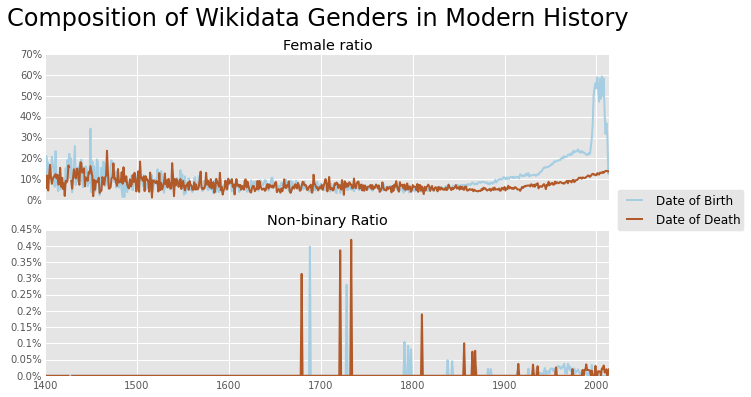
Curiously since about 1800 to present, the female ratio of biographies is greater when using the date of birth measure than the date of death measure. What is the interperation? Somehow recording female date of birth is more prominent in a way that recording date of death isn't. Although both ratios are rising, somehow date of birth is outstripping date of death. It would be great to investigate how much this is owed to recording practices and how much it is owed to social phenomenon.
Notice after about 1990, the spike is very large, and even crosses 50%. This is more statistical anomaly than anything else, since the number of humans with date of birth about 1990 is very small as you can see in the volumes plot. There are only 12,000 entries with date of birth in 1990 and only 199 biographies born in the year 2000. Even with discounting very recent trends of the last 20 years, which describe humans that are just entering adulthood or younger, the female ratio is rising exponentially. I was expecting to fit a logistics curve to the female percentage so that we could predict when we might reach parity, however that notion does not makes sense with what is being shown. Although there it may not necessarily indicated equity, fitting an exponential model to this percentage we can calculate when the female percentage would reach 50%. By our calculations it would be February 2034 when the exponential extrapolation would reach 50% female representation. But of course predicting growth of percentages can be lead to nonsensical results (as humourously shown in this xkcd comic). I suspect we will see a logistics model, but simply haven't encountered the inflection point of slowing rate of growth yet.
First some caveats as to method which we use in the next section.
 By DancingPhilosopher [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons[/caption]
By DancingPhilosopher [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons[/caption]We make a cross-tabulation of gender by culture. A Chi-squared test show the observed distributions of gender by culture to be significantly. We now graph the female percentage of biographies by culture.
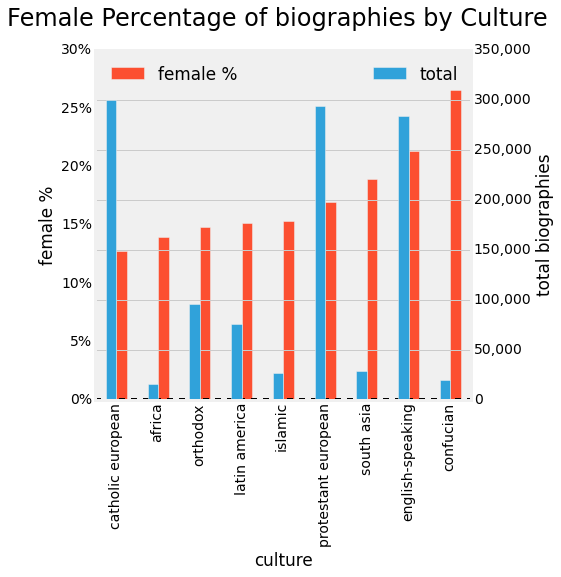
More than anything, I think what astounds most is the large different in the difference in absolute number of biographies by culture. The European and English-speaking world dominates by a large amount here. Although, it might be that European and English-Speaking biographies are simply more likely to be described in Wikidata at the moment, by some sort of quirk of the volunteer import process. Later we'll see how that affects German and Austrian items.
If we do inspect the female percentages as-is, we find a very high showing for in the Confucian culture. After talking to some Confucian-world Wikipedians on twitter (who I can't find now to credit) and fellow Wikipedia Researcher Hai-Yi Zhu from University of Minnesota, we produced the hypothesis that this is because the phenomenon of celebrity is larger in those cultures, and celebrity is more evenly gender-distributed. We will investigate the celebrity hypothesis in a bit. If you have another hypothesis, we welcome your input for testing.
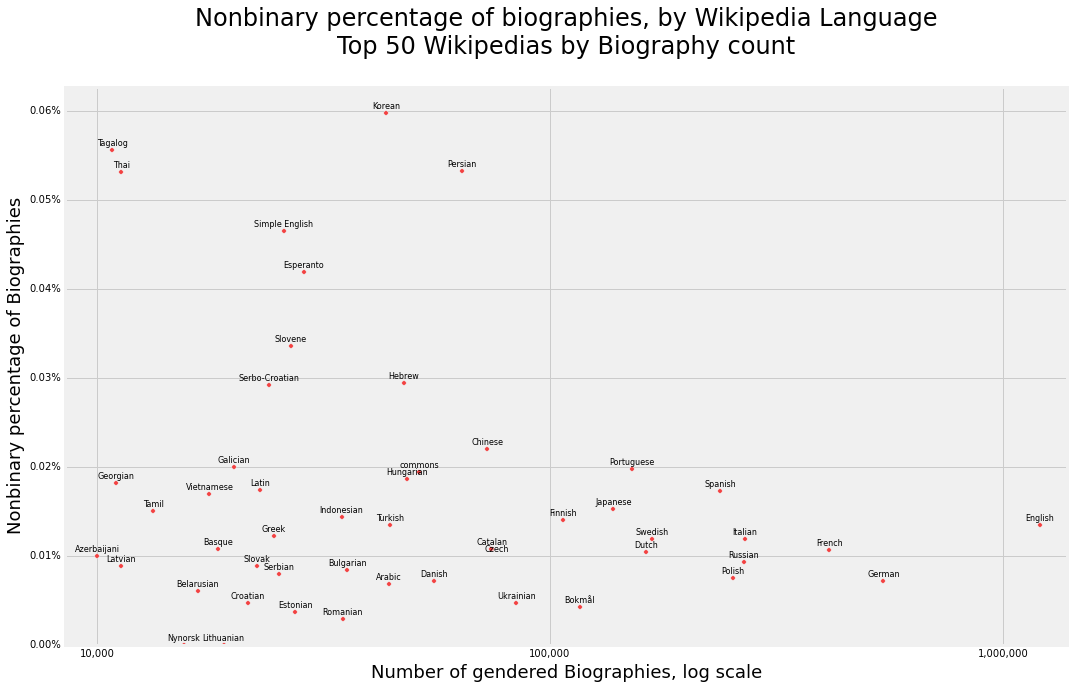
We provide the graph of nonbinary percentages of biographies by culture too. The cultures are ordered in the same way as the female graph for ease of comparison. Notice that the ordering is relatively similar to the female graph - so on the surface, recording female biographies is linked to recording nonbinary genders too.
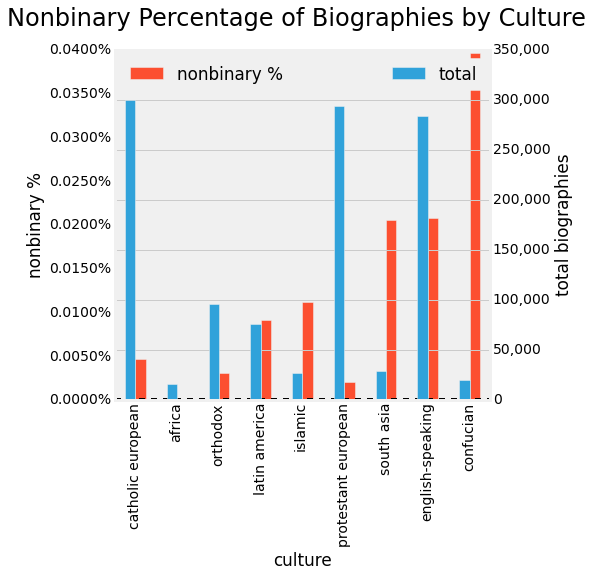
Lets mix all these variable now, by viewing the culture ratio trends over time. To note our sample size as we continue, only 951,101 or about 35% of total records have all of date of birth, culture, and gender data.
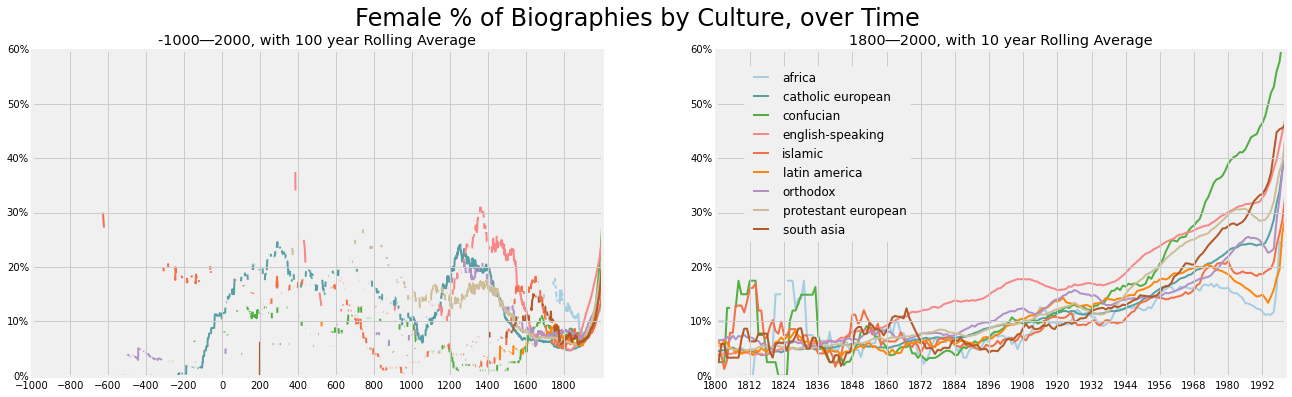
You can see that the recent past around 1800 is a low point for female recognition in all cultures and most of history in the past 3 millennia. Likewise visually it is evident that historical trends in different cultures have, while not reaching 50%, peaked at much higher percentages. In the modern historical graph, we can see a rise occurring for all cultures, and super-linear growth even for the Confucian and South Asian countries. .The sky-rocketing ratios after 1990 are less significant as noted above.
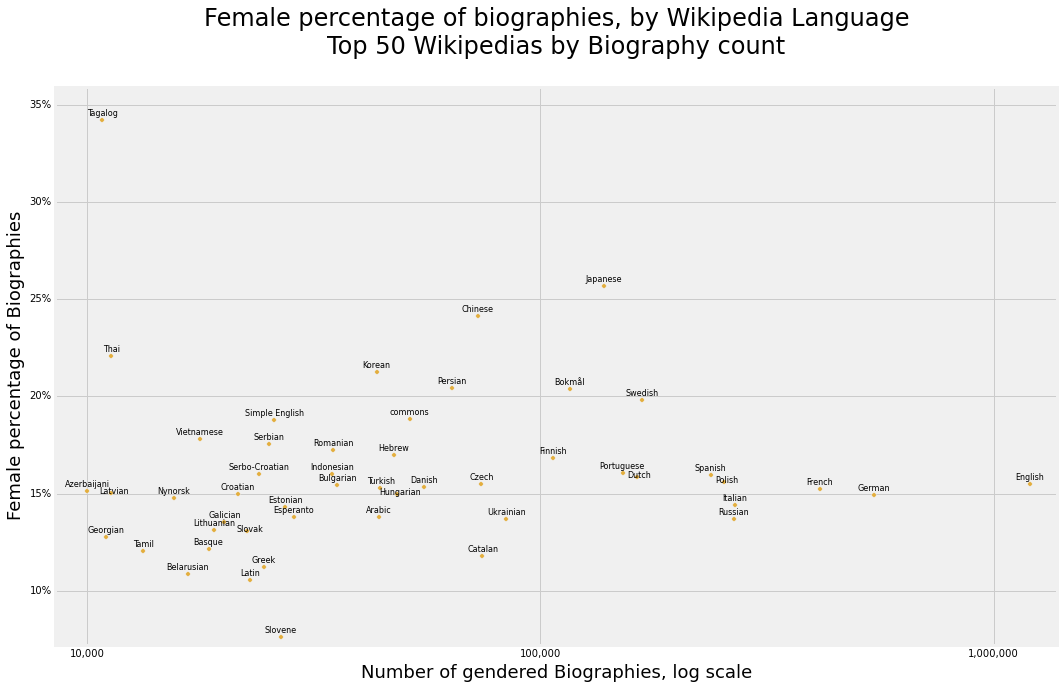
Now let us recall that there is one more dimension we have recorded, the sitelink dimension, which indicates whether or not for an item a Wikipedia language has an entry for it. To be clear, say for instance that Finnish Wikipedia has an article about a Japanese human; we would be commenting on Finnish Wikipedia. With this data we can analyse the female and nonbinary tendencies of a Language, not a nationality or culture.
Here we have plots that show the relative frequencies of female articles per Wikipedia language, versus the size of the language.
And again for nonbinary humans.
Notice in general there is no simple trend linking Wikipedia size to female representation. The visual technique with which I investigate here is to look at for the points whose magnitude from the origin is greatest. Mostly I see relatively a flat constant rate, with a few Wikipedias standing out a bit, like the Japanese, Chinese and Tagalog. So again we are seeing some evidence for Confucian and South Asian cultures being less gender biased when following the sitelink method analysis.
To sure up the idea of cultural influence in the sitelinks analysis we aggregate the languages into the nine World Cultures as before. In this case, since there are only about 280 languages, I assigned all of the languages by hand, rather than resorting to Mechanical Turk.
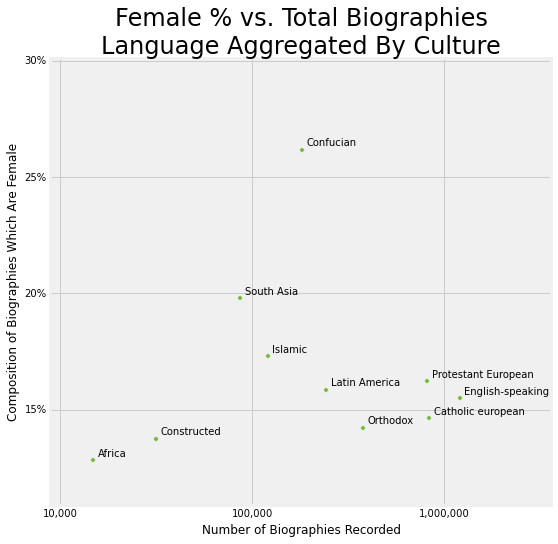
To clarify, the technique used here is that every Wikidata item counts towards a culture if a sitelink exists in at least one language associated with that culture. So if an article has language links to English, Chinese, and Japanese wikipedia, that item counts only once towards each of the English-speaking and Confucian categories.
Now we have a more coherent picture about which types of Wikipedias by language are focusing on female articles. And we do continue to see a high Confucian showing.
Let us test our celebrity hypothesis. For the Chinese, Japanese, Korean, Tagalog, Urdu, German and English Wikipedias, we retrieved the page content of each Biography from 1930 until 1989** (recall that there are very few Biographies with date of birth 1990 and higher).
We search for the English or foreign language words that are associated with celebrity. The dictionary used is:
{'jawiki': [u'俳優', u'選手', u'歌手', u'ミュージシャン', u'モデル', u'アイドル'],
'zhwiki': [u'演員', u'運動員', u'歌手', u'音乐家', u'模特兒', u'偶像'],
'kowiki' : [u'배우', u'선수', u'가수', u'음악가', u'모델', u'우상'],
'tlwiki': [u'artista', 'aktor', u'player', u'mang-aawit', u'musikero', u'modelo', u'idolo'],
'urwiki': [u'اردو', u'کھلاڑ', u'گلوکار' , u'موسیقار' , u'ماڈل', u'بت'],
'dewiki': [u'schauspieler' , u'spieler', u'Musiker', u'Sänger', u'Modell', u'Idol'],
'enwiki' :[u'actor', u'actress', u'player', u'singer', u'musician', u'model', u'idol']}
If you can provide better translations than Google's software, let me know. We consider a celebrity to be a biography that contains one of the above words within the first 200 characters of its Wikipedia entry.
Then we make a heatmap comparing the language, the decade and, the gender, and celebrity percentage.
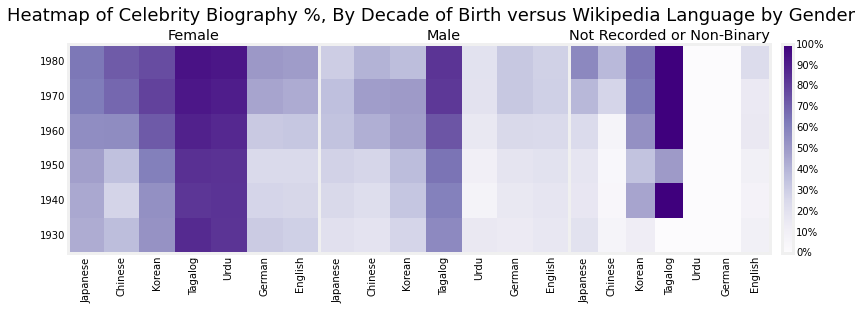
Using visual inspection, at first glance we can see that the female matrix is darker in general that the other two matrices. So recorded females are more likely to be celebrities among these languages.
Likewise you can see that in general the heatmap transitions to being darker at the top than bottom, so we have shifted to being more celebrity conscious in most languages in recent years.
Lastly we see some vertical-striped features showing that for instance Tagalog is prone to being celebrity conscious across gender and time.
To determine the significance of the effects we perform a logistic regression analysis in predicting the celebrity percentage variable. The coefficient matrix is printed below.
----------- ---------- --------- -------- ---------- ----------------------
coef std err z P>\|z\| \[95.0% Conf. Int.\]
decade 0.0236 0.013 1.823 0.068 -0.002 0.049
enwiki 0.0509 0.875 0.058 0.954 -1.664 1.766
jawiki 0.7763 0.837 0.927 0.354 -0.865 2.418
kowiki 1.3834 0.832 1.662 0.097 -0.248 3.015
tlwiki 3.0009 0.945 3.176 0.001 1.149 4.853
urwiki 0.8901 0.869 1.025 0.306 -0.813 2.593
zhwiki 0.5383 0.846 0.637 0.524 -1.119 2.196
female 1.3580 0.453 2.999 0.003 0.471 2.245
intercept -47.9056 25.368 -1.888 0.059 -97.626 1.815
----------- ---------- --------- -------- ---------- ----------------------
Depending on which arbitrary significance threshold you choose to use, we find different answers, but at least the female, and Tagalog, variables are significant with p<0.05. If we loosen the significance threshold slighly, decade, and Korean also become predictors. This lends a lot of credence to the notion that in the cases in which Women are recorded in Wikipedias, they have a strong tendency to be a celebrity.
Indexes are useful, but they are more useful as a group of compatible and comparable indexes. We compared our place of birth and citizenship data as it related to gender, to the World Economic Forum Gender Gap Index. The World Economic Forum uses its own methodology to produce a scalar value on the interval (0,1) to rank the gender equality of a country. To match to that format, we take the Wikidata data in the form of female composition of biographies by country.
We performed a calibration step to see which time window of data would produce our ranking of countries most closely being correlated with the World economic forum. If the Wikidata dataset is used with the time window only considering the biographies with date of birth between 1890 and 1990, the Spearman rank correlation is 0.31 with a p value of 0.03. That means that there is some founding for accepting the female composition of Wikidata items of humans associated with a country as an inequality index, because is significantly correlated with other respected inequality indexes.
Here is a sample of the two rankings side-by-side. We display the top 10 as per the World Economic Forum rank, and then the top 10 as per the Wikipedia Rank. You'll aslo see the associated WIGI rank, the raw scores for each, and the difference in the ranking.
World Economic Forum Top 10
Country WEF Rank Wikipedia Rank WEF Score Wikipedia Score Rank Difference
------------- ---------- ---------------- ----------- ----------------- -----------------
Iceland 1 30 0.8594 0.1895 -29
Finland 2 39 0.8453 0.1807 -37
Norway 3 22 0.8374 0.2142 -19
Sweden 4 1 0.8165 0.3452 3
Denmark 5 20 0.8025 0.2149 -15
Nicaragua 6 9 0.7894 0.2727 -3
Rwanda 7 108 0.7854 0.0962 -101
Ireland 8 64 0.7850 0.1586 -56
Philippines 9 3 0.7814 0.3228 6
Belgium 10 58 0.7809 0.1637 -48
WIGI Top 10
Country WEF Rank Wikipedia Rank WEF Score Wikipedia Score Rank Difference
---------------------------- ---------- ---------------- ----------- ----------------- -----------------
Sweden 4 1 0.8165 0.3452 3
South Korea 117 2 0.6403 0.3437 115
Philippines 9 3 0.7814 0.3228 6
Bahrain 124 4 0.6261 0.3171 120
Mauritius 106 5 0.6541 0.2941 101
People's Republic of China 87 6 0.6830 0.2812 81
Australia 24 7 0.7409 0.2760 17
Japan 104 8 0.6584 0.2732 96
Nicaragua 6 9 0.7894 0.2727 -3
Swaziland 92 10 0.6772 0.2593 82
We see how the rankings bear some similarity, but that the correlation is mild. Still we can take away that the notion of what the WEF is driving at with it's measure, and the number of female biographies that exist about humans in a country, as somewhat related idea.
The question of how well Wikidata accurately reflects all Wikipedias, is important to determine before addressing the question of how well Wikipedias reflect the world at-large.
During our research, we found a curious quirk in the way that nationality is recorded, and the story is instructive in showing that Wikidata still has a few artefacts of its bot-imported nature. A more in-depth analysis, I previously blogged about is available in a post about the "Wikidata and the Measure of Nationality".
In short, the idea centres around an early finding, that indicated that Protestant European humans seemed to disappear in the 1930s, when we were determining culture just using the "Place of Birth" property. It looked like this:
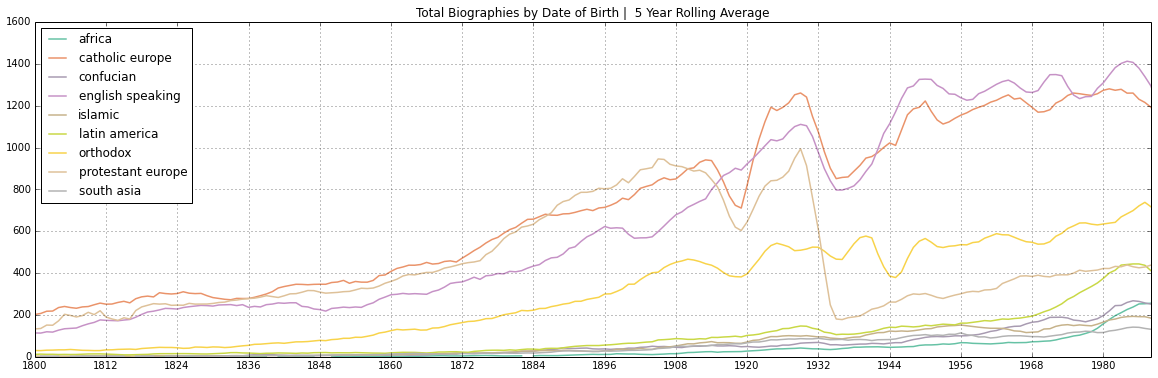
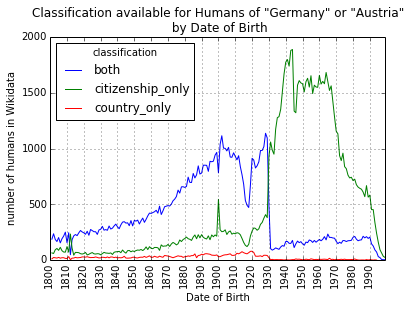
This is what lead us to investigate how nationalities were being classified on Wikidata. The next graphs show which humans have which classification method - by place of birth, citizenship, or both - for nationality. For Germanic humans we saw a large shift:
And for all other populations we witness no such thing:
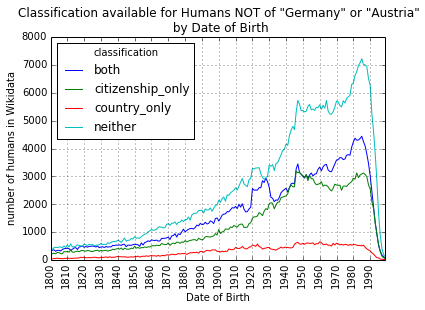
After publishing these finding, a Wikimedian wrote in to explain that the import of Germanic human data into Wikidata occured through a bot called "FischBot", and that the shift is likely only related to the way that that software operated. The moral being that we should still be vigilant in staying aware of the data quality in Wikidata.
It is not my intention to draw any large scale conclusions at the moment. For that I will wait until the publication of the paper for which this analysis is intended. Still I would be glad to hear any insights you might see until then.
We finished the writing the paper. An excerpt from the conclusion there:
Our research confirms that gender inequality is a phenomenon with a long history, but whose patterns can be analyzed and quantified on a larger scale than previously thought possible. Through the use of Inglehart-Welzel cultural clusters, we show that gender inequality can be analyzed with regards to world’s cultures. In the dimension studied (coverage of females and other genders in reference works) we show a steadily improving trend, through one with aspects that deserve careful follow up analysis (such as the surprisingly high ranking of the Confucian and South Asian clusters).
Tweet at me @notconfusing .
I programmed all of this research in using the IPython notebook, and it's all entirely open source and hopefully reproducible from https://github.com/notconfusing/WIGI.
I plan to start parsing and filtering Wikidata montly to provide updated data, which should be coming soon.
{kind=link}