::: {#notebook .border-box-sizing tabindex="-1"} ::: {#notebook-container .container} ::: {.cell .border-box-sizing .text_cell .rendered} ::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} [For a better reading experience read this post in the IPython Notebook Viewer.]{style="font-size: 18pt;"}
::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} I recently got back from the Mediawiki Hackathon in Zürich, where I was once again energized and inspired by the Wikidata Dev Team and Community. In chatting, they reminded me of analyses I ran in March 2013, Sex Ratios and Wikidata Parts I and II, about the state of a controversial Wikidata Property - P21 a.k.a. "sex or gender". They suggested it was about time to reinvestigate.
Since Part I and II a lot has happened: the property has been renamed (from "sex" to "sex or gender"), it's database constraints have been changed (from 3 accepted values to 13), and of course Wikidata has continued to proliferate (now about 400 million triples).
Therefore a few questions are begged:
That last question is not like the others, but comes from exploring the new Wikidata Toolkit, a library for parsing Wikidata dumps. Trying to stretch the imagination of what can be done with Wikidata data is a new hobby of mine, and I am giving a talk about it at Wikiconference USA, titled "Answering Big Questions with Wikidata". For now the Wikidata Toolkit is at version 0.1.0, which is still not entirely feature-complete, but works perfectly to extract complete, daily-fresh data. For my own convenience I subset the data in java and then json export (github link), allowing me to munge it in Python with the "Pandas" library, which is exactly what you see here.
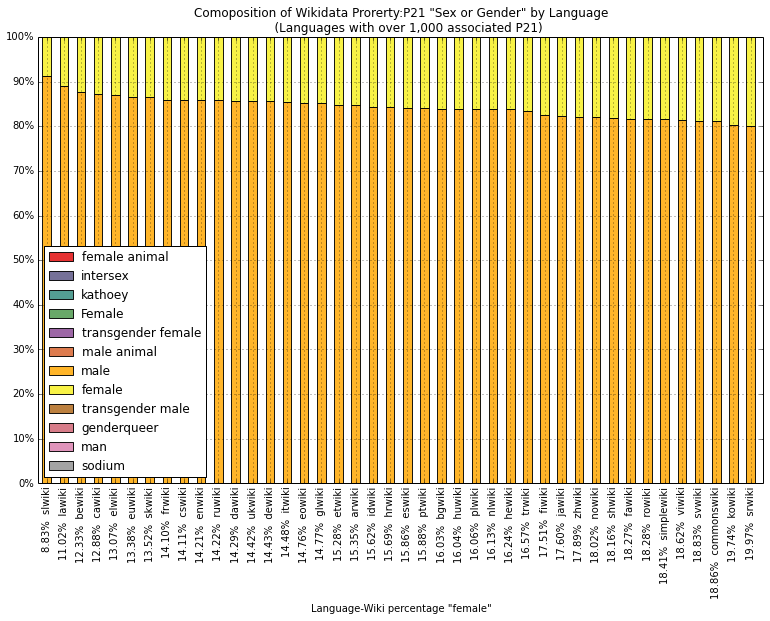
The biggest change in my opinion is the broadening - (but still not broad enough in my opinion - of the "accepted values" of the property. Let's see what wikidatians are using these days. Below are the English titles of the QIDs and how many different wikidata-linked-wikis are connected to an item utilising that value. ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [1]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} {english_label(qid): language_count for qid, language_count in used_sexes_count.iteritems()} ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[1]: :::
::: {.output_text .output_subarea .output_pyout} {u'Female': 89, u'female': 367, u'female animal': 55, u'genderqueer': 23, u'intersex': 51, u'kathoey': 10, u'male': 395, u'male animal': 66, u'man': 3, u'sodium': 1, u'transgender female': 63, u'transgender male': 24} ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} So without delving into the validity of the classifications used, which I'll adress later, we see 12 classifications in active duty. Compare this to the begrudging trinary we had a year ago, or Facebook's announcement to use about 50 classifcations. We can also see that there are two heavily used classifications - by the metric of number of wikis using them - called 'male' (395 wikis) and 'female' (367 wikis). Why the difference in the number of wikis? We must clarify what we mean by use. We are talking about a Wikipedia, or a Wikisource, or a Wikivoyage instance that has a article that is linked to a Wikidata item which has a P21 "sex or gender" property. So that means that there are 28 or more Wikimedia wikis which have an article which Wikidata claims is about a 'male', but have no articles about 'female's. But there are also a lot of tiny wikis out there, which might explain this discrepancy.
Let's restrict our data set only to those Wikis which have 1,000 or more articles that are linked to a Wikidata item with a P21 property. There are 42 such wikis as of May 2014. Now we plot, the ratios or composition of the values of this property in each of those 42 wikis. ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [2]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} show_by_lang_plot()
::: {.prompt .input_prompt} Out[2]: ::: ::: ::: ::: :::
::: {.output_wrapper}
 :::
:::
:::
:::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} As is visually evident, only the 'male' and 'female' categories are large enough to appear in the plot (later on we investigate this numerically). Therefore the chart is ordered by the 'female' percentage which ranges from 8.83% - Slovenian Wikipedia, to 19.97% - Serbian Wikipedia. English Wikipedia, the largest Wikipedia by article count comes in at 14.21% which is in the lowest quarter. Wikimedia commons, the only non-Wikipedia represented here performs relatively well at 18.86%.
These percentages are still systematically low, and tell a story that we've long known about representational bias. But what about the momentum? What difference are our efforts at uncovering and addressing systemic bias producing? ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} Comparing May 2013 to March 2014¶ {#Comparing-May-2013-to-March-2014}
::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} These next tables inspect how a language's composition changed in the previous year. We consider all languages that had at least 1,000 P21 associated properties in both years. I'll disclaim that the differences come from the a Wikipedia's content changing, but also from Wikidata becoming more connected to those different wikis. It's not possible at the moment to disentangle these two causes. Another complicating factor, that we will investigate later on, is the growth of the neither-male-nor-female entries which could account for this drop - but (spoiler) they don't.
In each table there is the percentage female from May 2013, from March 2014, and the 'change%' that this represents, "year-over-year" (even though its about 14 months).
We sort by 'change%', and first look at the largest losses in 'female' percentage. ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html}
::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [17]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} diffdf.sort(columns='change%', ascending=True)[['female_may2013','female_march2014','change%']].head(10) ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[17]: :::
::: {.output_html .rendered_html .output_subarea .output_pyout} ::: {style="max-height: 1000px; max-width: 1500px; overflow: auto;"}
| ::: ::: ::: ::: ::: ::: ::: ::: | female_may2013 | female_march2014 | change% |
|---|---|---|---|
| lang | |||
| enwiki | 0.1845 | 0.142132 | -22.96 |
| gawiki | 0.1456 | 0.118133 | -18.86 |
| afwiki | 0.1406 | 0.115850 | -17.60 |
| cswiki | 0.1705 | 0.141063 | -17.27 |
| frwiki | 0.1658 | 0.141045 | -14.93 |
| zhwiki | 0.2062 | 0.178885 | -13.25 |
| itwiki | 0.1667 | 0.144760 | -13.16 |
| hywiki | 0.1633 | 0.141859 | -13.13 |
| ruwiki | 0.1627 | 0.142226 | -12.58 |
| htwiki | 0.0531 | 0.047382 | -10.77 |
10 rows × 3 columns
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} English Wikipedia fell the most in the percentage of it's P21 properties being marked 'female'. The reprsentation of articles marked 'female', compared to all others, dropped by about 4% in absolute terms, which is -23% year-on-year.
Also of note, the Hatian Wikipedia, the previous worst at 5.3% slid to retain the dubious title at 4.7%.
What about the other end of the chart? ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html}
::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [18]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} diffdf.sort(columns='change%', ascending=False)[['female_may2013','female_march2014','change%']].head(10) ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[18]: :::
::: {.output_html .rendered_html .output_subarea .output_pyout} ::: {style="max-height: 1000px; max-width: 1500px; overflow: auto;"}
| ::: ::: ::: ::: ::: ::: | female_may2013 | female_march2014 | change% |
|---|---|---|---|
| lang | |||
| urwiki | 0.1319 | 0.486671 | 268.97 |
| ocwiki | 0.1261 | 0.159599 | 26.57 |
| mlwiki | 0.1636 | 0.202758 | 23.93 |
| bnwiki | 0.1313 | 0.161183 | 22.76 |
| mznwiki | 0.1041 | 0.125305 | 20.37 |
| arzwiki | 0.2392 | 0.287158 | 20.05 |
| ltwiki | 0.1190 | 0.142340 | 19.61 |
| arwiki | 0.1293 | 0.153516 | 18.73 |
| warwiki | 0.1003 | 0.116598 | 16.25 |
| tlwiki | 0.2943 | 0.340477 | 15.69 |
10 rows × 3 columns
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} Urdu Wikipedia gained a massive 268% year-on-year increase in their 'female' ratio. Now 49% of their P21-tagged articles have label 'female'. Does anyone closer to this community know if there were any tagging efforts?
Tagalog Wiki, previous best, continued to increase to 34% of their P21-tagged articles having label 'female'.
There has been a lot of movement in sex-ratios of different languages. As stated earlier this is also due in some part to the maturing of wikidata clusters. Next year we will be able to see if there is a deceleration in these ratios moving.
We now move on to invesitage the second confounding factor, the increase in accepted "sex or gender" values. ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html}
::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} As we saw earlier, there are now 12 properties that are being used to describe P21. In May 2013 the only non-male-female term was intersex, and P21 said that you should be one of male, female, or intersex. I was quite angered by this prescriptiveness, but with help from online discussions, and with thanks to the gendergap mailing list some of those policies have changed. This now is the "sex or gender" property, rather than just "sex" which I consider a mixed result - quite literally. I am pleased that there is one instance of this value that is "sodium", because I support this prorpety allowing any value. To be clear, what an "accepted" value means, is that periodically a check is run on the database, and non-accepted values are compiled into a list for user-attention. So robot won't fight you if you use an unaccepted value, but the fodder is there for a human combatant.
Two more of the new values mention "animal" because in Czech and Finnish, there are seperate words to describe sexes of non-human animals. And of course Wikipedia has articles on famous animals too.
Some others like 'Female' (a 1933 film), and 'man' are probably due to human tagging errors.
Below are the wiki's which have the highest number of non 'male' or 'female' values as represented by the new column at the end "non_MF%". As you can see none of them exceed two-tenths of 1%. So the upper analysis of year-on-year-change could at most be influenced by error range of ±0.2%. ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [130]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} top_non_MF.sort('non_MF%', ascending=False) ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[130]: :::
::: {.output_html .rendered_html .output_subarea .output_pyout} ::: {style="max-height: 1000px; max-width: 1500px; overflow: auto;"} wiki non_MF%
male animal yiwiki 0.181159 transgender female urwiki 0.092994 Female mgwiki 0.080321 genderqueer zh_min_nanwiki 0.066445 intersex ckbwiki 0.058754 transgender male arzwiki 0.042105 female animal hywiki 0.038812 kathoey thwiki 0.012922 man jawiki 0.001523 sodium eswiki 0.000990
10 rows × 2 columns ::: ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} Intriguingly, Urdu which tops the charts in year-on-year 'female' increase also the leader in higest ratio of "transgender female" at nearly one-tenth of one percent, or about 1 in a 1000. This lends credence to the idea that some Urdu Wikipedians have been busy. ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html}
::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} Markus Krötzsch, instigator of the Wikidata Toolkit, on which this research rests, talks about the complexity of Wikidata data. Convincingly he discusses why full unstructured access to the data is important - creative queries. Both star and tree shaped queries should be possible and at the users discretion.
One less trivial query I wanted to cook up was - "on items with a P21 value what are the properties by per item, by P21 value?" Framed in English, are wikidata items about males data-richer? ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [44]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} sex_props_df[sex_props_df['item_count'] > 5] ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[44]: :::
::: {.output_html .rendered_html .output_subarea .output_pyout} ::: {style="max-height: 1000px; max-width: 1500px; overflow: auto;"} item_count total_props props_per_item
transgender female 41 398 9.707317 intersex 8 88 11.000000 female animal 6 44 7.333333 male animal 55 385 7.000000 genderqueer 8 63 7.875000 female 122288 738962 6.042801 male 768646 4816357 6.266028
7 rows × 3 columns ::: ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} The above chart displays the properties per item, for all P21 values that occur 5 or more times. The results are telling, on avereage items with the 'male' property have 6.27 properties, and those with 'female' 6.04. It's also worth mentioning that 'transgender female' averages 9.71 properties per item. ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html}
::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} Without becoming too political, the biases that exist in Wikipedia's representation of the world are systemic, and appreciable. We can see from our year-on-year calculations that there is movement in this dataset - albeit not always for the better. The representation of non-male-female items I suspect is lower than what a sample from the wolrd would indicate, but I don't have any statistical reference, and would welcome suggestions on datasets with which to compare. Lastly we showed that not only in representation, but also in attention given to each item, underepresnted 'sex or genders' are less semantically-described.
Questions and criticism greatly recieved,
‽notconfusing ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} Start of Supporting Code¶ {#Start-of-Supporting-Code}
::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [1]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} import json from collections import defaultdict import pandas as pd import pywikibot import decimal NOPLACES = decimal.Decimal(10) 0 TWOPLACES = decimal.Decimal(10) -2 %pylab inline ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt} :::
::: {.output_subarea .output_stream .output_stderr .output_text} VERBOSE:pywiki:Starting 1 threads... ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [20]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} norm_sex[sexdf['total']>1000].sort(columns='non_MF', ascending=False).head(10) ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[20]: :::
::: {.output_html .rendered_html .output_subarea .output_pyout} ::: {style="max-height: 1000px; max-width: 1500px; overflow: auto;"} female animal intersex kathoey Female transgender female male animal male female transgender male genderqueer man sodium non_MF
zh_min_nanwiki 0.000000 0.000000 0.000000 0.000664 0.000000 0.000664 0.787375 0.210631 0.000000 0.000664 0 0 0.001993 yiwiki 0.000000 0.000000 0.000000 0.000000 0.000000 0.001812 0.897645 0.100543 0.000000 0.000000 0 0 0.001812 cywiki 0.000371 0.000000 0.000000 0.000186 0.000371 0.000000 0.820375 0.178326 0.000186 0.000186 0 0 0.001299 ckbwiki 0.000000 0.000588 0.000000 0.000000 0.000588 0.000000 0.893067 0.105758 0.000000 0.000000 0 0 0.001175 thwiki 0.000000 0.000000 0.000129 0.000129 0.000388 0.000388 0.788345 0.210492 0.000129 0.000000 0 0 0.001163 mswiki 0.000000 0.000000 0.000000 0.000223 0.000223 0.000446 0.802679 0.196205 0.000223 0.000000 0 0 0.001116 ruwikiquote 0.000000 0.000000 0.000000 0.000552 0.000000 0.000000 0.909492 0.089404 0.000000 0.000552 0 0 0.001104 mlwiki 0.000270 0.000270 0.000000 0.000270 0.000270 0.000000 0.796161 0.202758 0.000000 0.000000 0 0 0.001081 eowiki 0.000125 0.000187 0.000062 0.000062 0.000374 0.000249 0.851300 0.147640 0.000000 0.000000 0 0 0.001060 kowiki 0.000075 0.000075 0.000038 0.000038 0.000491 0.000113 0.801608 0.197373 0.000075 0.000113 0 0 0.001019
10 rows × 13 columns ::: ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [3]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} jsonfile = open('lang_sex.json','r') bigdict = json.load(jsonfile) lang_sex = defaultdict(dict) for keystring, count in bigdict.iteritems(): lang, sex = keystring.split('--') lang_sex[lang][sex] = count
used_sexes = defaultdict(list)
for lang, sex_dict in lang_sex.iteritems():
for sex in sex_dict.iterkeys():
used_sexes[sex].append(lang)
used_sexes_count = {sex: len(lang_list) for sex, lang_list in used_sexes.iteritems()}
::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [6]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} sexdf = pd.DataFrame.from_dict(lang_sex, orient='index') sexdf = sexdf.fillna(value=0) #sexdf.plot(kind='bar', stacked=True, figsize=(10,10)) Norm_sex is not "normal" sex, but rather the Sex-data normed into percentages. norm_sex = sexdf.apply(lambda col: col / float(col.sum()), axis=1) ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [8]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} #Tranforming QIDs into English labels. enwp = pywikibot.Site('en','wikipedia') wikidata = enwp.data_repository()
def english_label(qid):
page = pywikibot.ItemPage(wikidata, qid)
data = page.get()
return data['labels']['en']
sex_qs = [str(q) for q in norm_sex.columns]
sex_labels = [english_label(sex_q) for sex_q in sex_qs]
norm_sex.columns = sex_labels
::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt} :::
::: {.output_subarea .output_stream .output_stderr .output_text} VERBOSE:pywiki:Found 1 wikidata:wikidata processes running, including this one. ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [9]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} #norm_sex.index = [label.replace('wiki','') for label in norm_sex.index] #comparing by total between two different dataframes requires #that norm_sex has not had any rows modified since it was created from sexdf sexdf['total'] = sexdf.sum(axis=1) fs1000 = norm_sex[sexdf['total']>10000].sort('female', ascending=True) ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [11]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} def show_by_lang_plot(): fsplot = fs1000.plot(kind='bar', stacked=True, legend=True, figsize=(13,8), alpha=0.9, ylim=(0,1), title= '''Comoposition of Wikidata Prorerty:P21 "Sex or Gender" by Language (Languages with over 1,000 associated P21)''', colormap='Set1')
plt.yticks(linspace(0, 1, num=11), [str(decimal.Decimal(x * 100).quantize(NOPLACES))+'%' for x in arange(0,1.1,0.1)])
ticklocs, langs = plt.xticks()
langstrs = [str(decimal.Decimal(norm_sex.loc[lang.get_text()]['female']* 100).quantize(TWOPLACES))+'% '+ lang.get_text() for lang in langs]
plt.xticks(ticklocs, langstrs)
plt.xlabel('Language-Wiki percentage "female"')
::: ::: ::: ::: :::
::: {.cell .border-box-sizing .text_cell .rendered} ::: {.prompt .input_prompt} :::
::: {.inner_cell} ::: {.text_cell_render .border-box-sizing .rendered_html} For your edification, the full data, and not just the 'female' percentages. ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [15]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} fs1000 ::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt .output_prompt} Out[15]: :::
::: {.output_html .rendered_html .output_subarea .output_pyout} ::: {style="max-height: 1000px; max-width: 1500px; overflow: auto;"} female animal intersex kathoey Female transgender female male animal male female transgender male genderqueer man sodium
slwiki 0.000074 0.000000 0.000000 0.000074 0.000074 0.000074 0.911398 0.088307 0.000000 0.000000 0.000000 0.00000 lawiki 0.000060 0.000060 0.000000 0.000060 0.000180 0.000120 0.889302 0.110219 0.000000 0.000000 0.000000 0.00000 bewiki 0.000000 0.000000 0.000000 0.000099 0.000000 0.000099 0.876528 0.123273 0.000000 0.000000 0.000000 0.00000 cawiki 0.000026 0.000000 0.000000 0.000026 0.000103 0.000129 0.870905 0.128786 0.000026 0.000000 0.000000 0.00000 elwiki 0.000000 0.000000 0.000000 0.000068 0.000068 0.000068 0.869061 0.130734 0.000000 0.000000 0.000000 0.00000 euwiki 0.000080 0.000000 0.000000 0.000080 0.000080 0.000239 0.865686 0.133837 0.000000 0.000000 0.000000 0.00000 skwiki 0.000078 0.000000 0.000000 0.000078 0.000078 0.000078 0.864363 0.135245 0.000078 0.000000 0.000000 0.00000 frwiki 0.000020 0.000025 0.000000 0.000005 0.000107 0.000097 0.858680 0.141045 0.000005 0.000015 0.000000 0.00000 cswiki 0.000048 0.000000 0.000000 0.000024 0.000096 0.000096 0.858648 0.141063 0.000024 0.000000 0.000000 0.00000 enwiki 0.000009 0.000012 0.000002 0.000002 0.000069 0.000052 0.857699 0.142132 0.000007 0.000014 0.000002 0.00000 ruwiki 0.000038 0.000019 0.000010 0.000010 0.000077 0.000077 0.857515 0.142226 0.000019 0.000010 0.000000 0.00000 dawiki 0.000036 0.000073 0.000000 0.000036 0.000109 0.000073 0.856768 0.142904 0.000000 0.000000 0.000000 0.00000 ukwiki 0.000062 0.000031 0.000000 0.000031 0.000062 0.000031 0.855573 0.144178 0.000031 0.000000 0.000000 0.00000 dewiki 0.000013 0.000006 0.000003 0.000003 0.000034 0.000047 0.855591 0.144277 0.000013 0.000013 0.000000 0.00000 itwiki 0.000006 0.000028 0.000000 0.000006 0.000090 0.000107 0.854986 0.144760 0.000011 0.000006 0.000000 0.00000 eowiki 0.000125 0.000187 0.000062 0.000062 0.000374 0.000249 0.851300 0.147640 0.000000 0.000000 0.000000 0.00000 glwiki 0.000082 0.000082 0.000000 0.000082 0.000329 0.000164 0.851602 0.147658 0.000000 0.000000 0.000000 0.00000 etwiki 0.000079 0.000079 0.000000 0.000079 0.000079 0.000237 0.846676 0.152771 0.000000 0.000000 0.000000 0.00000 arwiki 0.000040 0.000040 0.000000 0.000040 0.000079 0.000079 0.846166 0.153516 0.000000 0.000040 0.000000 0.00000 idwiki 0.000208 0.000052 0.000000 0.000052 0.000104 0.000156 0.843220 0.156156 0.000052 0.000000 0.000000 0.00000 hrwiki 0.000078 0.000078 0.000000 0.000078 0.000078 0.000156 0.842670 0.156863 0.000000 0.000000 0.000000 0.00000 eswiki 0.000030 0.000040 0.000000 0.000010 0.000109 0.000079 0.841094 0.158589 0.000020 0.000020 0.000000 0.00001 ptwiki 0.000043 0.000043 0.000000 0.000014 0.000199 0.000114 0.840760 0.158785 0.000014 0.000028 0.000000 0.00000 bgwiki 0.000091 0.000045 0.000000 0.000045 0.000091 0.000181 0.839242 0.160305 0.000000 0.000000 0.000000 0.00000 huwiki 0.000120 0.000040 0.000000 0.000040 0.000200 0.000200 0.839014 0.160386 0.000000 0.000000 0.000000 0.00000 plwiki 0.000031 0.000021 0.000000 0.000010 0.000063 0.000094 0.839206 0.160575 0.000000 0.000000 0.000000 0.00000 nlwiki 0.000041 0.000027 0.000000 0.000014 0.000082 0.000123 0.838302 0.161343 0.000014 0.000041 0.000014 0.00000 hewiki 0.000085 0.000042 0.000000 0.000042 0.000297 0.000127 0.836914 0.162449 0.000000 0.000042 0.000000 0.00000 trwiki 0.000076 0.000038 0.000000 0.000038 0.000114 0.000191 0.833810 0.165656 0.000038 0.000038 0.000000 0.00000 fiwiki 0.000060 0.000060 0.000020 0.000020 0.000099 0.000079 0.824523 0.175100 0.000040 0.000000 0.000000 0.00000 jawiki 0.000030 0.000030 0.000015 0.000015 0.000167 0.000107 0.823550 0.176039 0.000000 0.000030 0.000015 0.00000 zhwiki 0.000087 0.000029 0.000029 0.000029 0.000261 0.000145 0.820476 0.178885 0.000029 0.000029 0.000000 0.00000 nowiki 0.000020 0.000020 0.000000 0.000020 0.000082 0.000082 0.819593 0.180183 0.000000 0.000000 0.000000 0.00000 shwiki 0.000073 0.000073 0.000000 0.000073 0.000367 0.000000 0.817768 0.181571 0.000000 0.000073 0.000000 0.00000 fawiki 0.000066 0.000033 0.000033 0.000033 0.000332 0.000033 0.816748 0.182721 0.000000 0.000000 0.000000 0.00000 rowiki 0.000096 0.000048 0.000000 0.000048 0.000048 0.000096 0.816821 0.182844 0.000000 0.000000 0.000000 0.00000 simplewiki 0.000051 0.000051 0.000000 0.000051 0.000306 0.000102 0.815151 0.184084 0.000051 0.000153 0.000000 0.00000 viwiki 0.000093 0.000093 0.000000 0.000093 0.000093 0.000186 0.813103 0.186247 0.000000 0.000093 0.000000 0.00000 svwiki 0.000042 0.000042 0.000000 0.000014 0.000111 0.000056 0.811433 0.188275 0.000014 0.000014 0.000000 0.00000 commonswiki 0.000045 0.000000 0.000000 0.000045 0.000089 0.000268 0.810849 0.188614 0.000045 0.000045 0.000000 0.00000 kowiki 0.000075 0.000075 0.000038 0.000038 0.000491 0.000113 0.801608 0.197373 0.000075 0.000113 0.000000 0.00000 srwiki 0.000074 0.000074 0.000000 0.000074 0.000074 0.000223 0.799718 0.199688 0.000000 0.000074 0.000000 0.00000
42 rows × 12 columns ::: ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [16]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} maydf = pd.read_table('may2013.csv',sep=',', index_col=0) maydf['female'] = maydf['perc'] / 100.0 diffdf = maydf.join(other=norm_sex,how='inner',lsuffix='_may2013', rsuffix='_march2014') diffdf['change%'] = (diffdf['female_march2014'] - diffdf['female_may2013']) / diffdf['female_may2013'] diffdf['change%'] = diffdf['change%'].apply(lambda x: decimal.Decimal(x * 100).quantize(TWOPLACES) ) ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [19]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} non_MF_cols = [col for col in norm_sex.columns if col not in ['male','female']] norm_sex['non_MF'] = norm_sex[non_MF_cols].sum(axis=1) ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [128]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} top_non_MF_dict = dict() for s in non_MF_cols: t = norm_sex[sexdf['total']>1000].sort(columns=s, ascending=False)[s].head(1) top_non_MF_dict[s] = {'wiki':t.index[0],'non_MF%':t[0]*100} top_non_MF = pd.DataFrame.from_dict(data=top_non_MF_dict, orient='index') ::: ::: ::: ::: :::
::: {.cell .border-box-sizing .code_cell .rendered} ::: {.input} ::: {.prompt .input_prompt} In [43]: :::
::: {.inner_cell} ::: {.input_area} ::: {.highlight} jsonfile = open('sex_propcount.json','r') sex_props_json = json.load(jsonfile) sex_props = defaultdict(dict) for keystring, count in sex_props_json.iteritems(): sex, prop = keystring.split('_') sex_props[sex][prop] = count
sex_props_df = pd.DataFrame.from_dict(sex_props, orient='index')
sex_qs = [str(q) for q in sex_props_df.index]
sex_labels = [english_label(sex_q) for sex_q in sex_qs]
sex_props_df.columns = ['item_count', 'total_props']
sex_props_df.index = sex_labels
sex_props_df['props_per_item'] = sex_props_df['total_props'] / sex_props_df['item_count']
::: ::: ::: :::
::: {.output_wrapper} ::: {.output} ::: {.output_area} ::: {.prompt} :::
::: {.output_subarea .output_stream .output_stderr .output_text} VERBOSE:pywiki:Found 1 wikidata:wikidata processes running, including this one. ::: ::: ::: ::: :::