At Wikimania 2013 Hong Kong during a Wikidata presentation, there was a small nod to a hidden but useful feature of Wikidata - multi-language display. Wikidata items are language-agnostic in concept, they are identified by their Q-ID which is displayed in the URL. Depending on which language your interface is set to independent labels, descriptions, and aliases will be displayed in that language. With this feature you can enable the labels, descriptions, and aliases of many languages to appear at once.
This is a boon, because it allows you to better peer into the structural translation the names of over 14,000,000 Wikidata concepts into 270 languages. Needless to say such a corpus will be really useful for a variety of multilingual research. In fact I have already populated over 14,000 Wikidata labels and aliases, by bot, using data from the Library of Congress, as I explain later on. 14,000 labels and aliases are really a drop in the bucket, which is my this small-work-unit task is so necessary to activate.
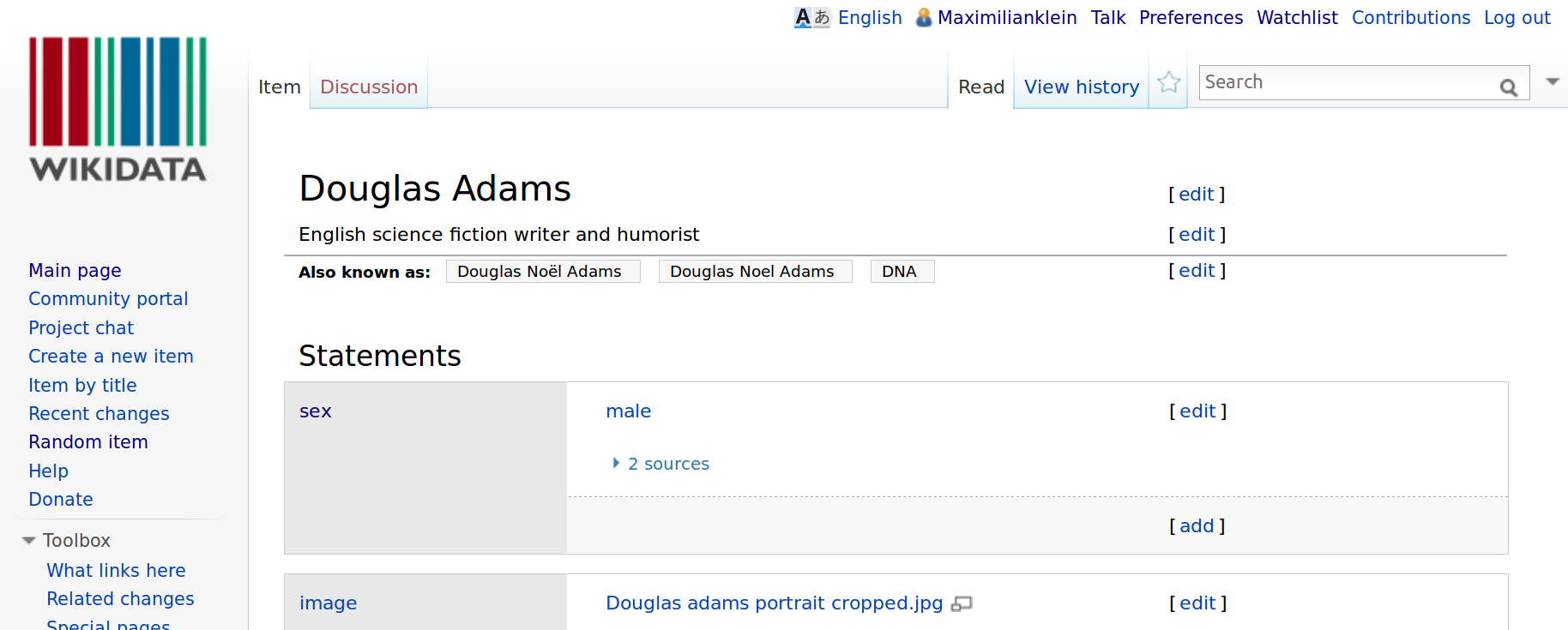 Default view of Wikidata with Language set to English.
Default view of Wikidata with Language set to English.
Douglas Adams is a favourite target for demonstrations on Wikidata because his Q-ID is easy to remember if you're geeky enough. If you click on the language selector in the top row, you could change your language to see Wikidata, and item labels, descriptions and aliases displayed in another language.
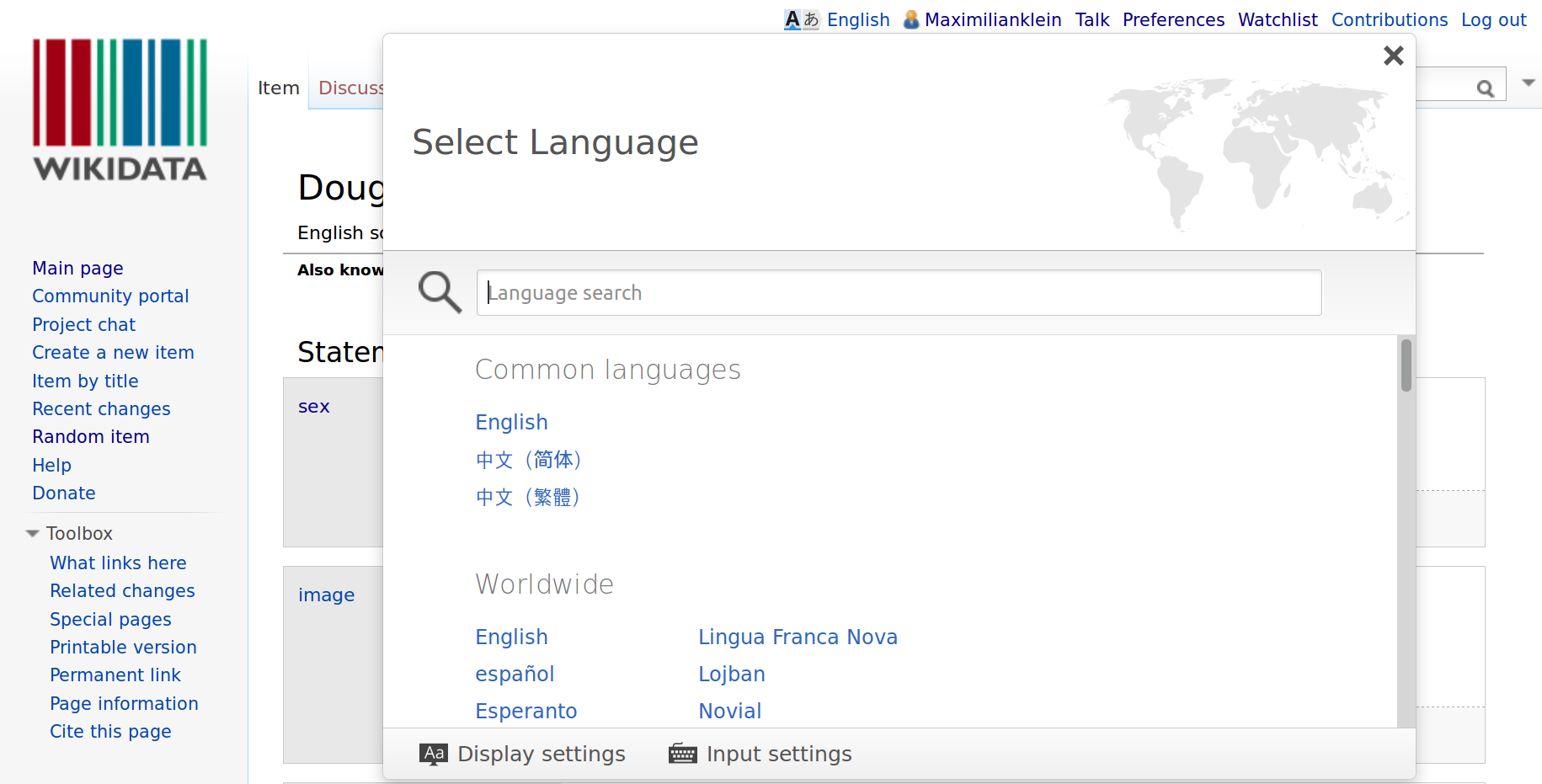 The language selector active.
The language selector active.
Now, in order to enable the multiple languages at the same time, we make a customization to our user page. Go to your user page which is also in the top row of links and edit the page. In addition to any text there we add at line of code which will have the form:
{{#babel:(language code)-(level)|(language code)-(level)|...}}
Language codes are short strings representing languages, you can use any ISO 639-1 code. Level is a rating from 0-5 or N, with 0 being not able to speak, 5 being a professional translator, and N being native. The level setting will change the graphical display on your user page but has no effect on your item-view, it's simply controlled by which languages are present in this babel box.
In my case for instance I have:
{{#babel:en-N|he-2|es-2|jbo-1}}
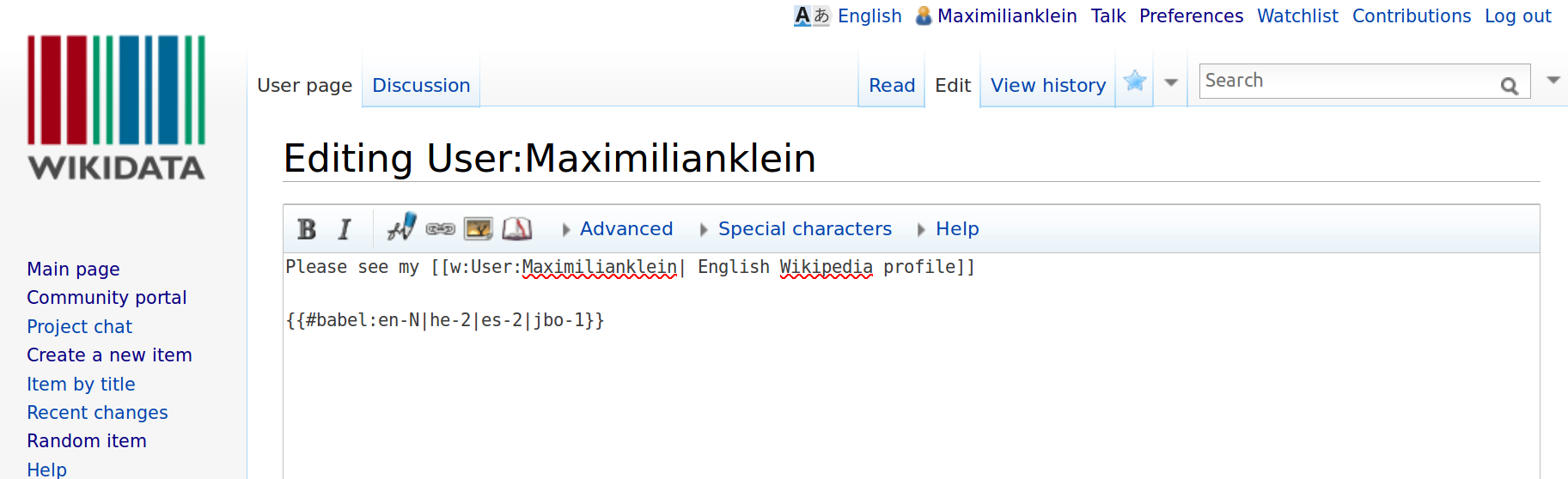 Adding the call to babel in your user page.
Adding the call to babel in your user page.
After we save our user page, we can go back to the Douglas Adams item. And see that there is a new page section displayed In other languages. For each language in your babel box, you will have the chance to edit the label and description.
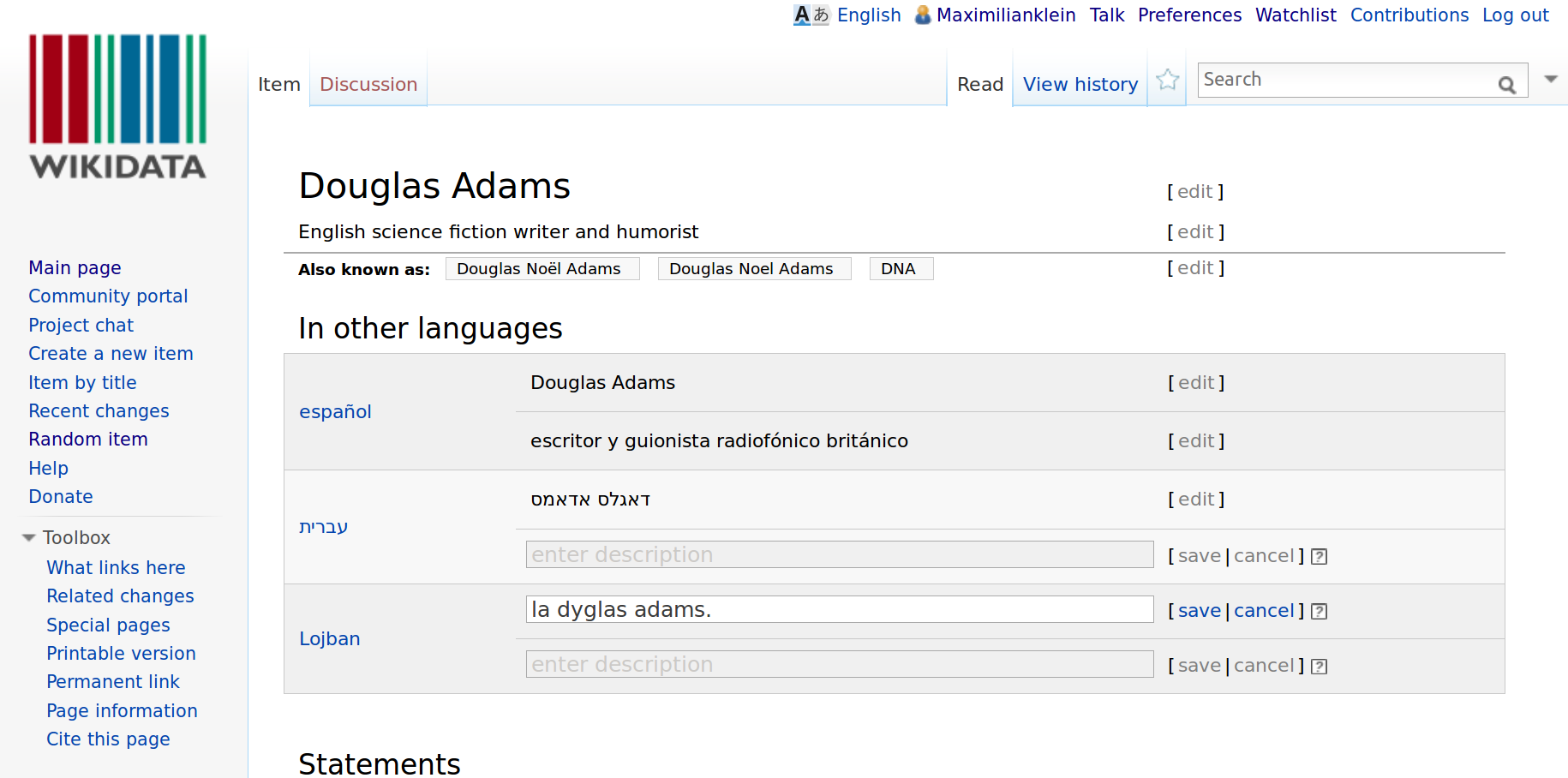 The new view with Babel active. Able to edit in Spanish, Hebrew, and Lojban as well.
The new view with Babel active. Able to edit in Spanish, Hebrew, and Lojban as well.
If you speak multiple languages this is useful because even if you cannot read the description - or one does not exist - in a particular language you may be able to read it in another language that you also know. Plus, if you feel so inclined you can quickly add to the label completeness goal with minimal clicks.
You can probably tell by now that I'm obsessed with label completeness. It's important for understanding what we don't understand. Even though there are 4 million articles in English Wikipedia, there are 10 million more Wikidata items. With label completeness we can understand which articles exist in other languages but not in our own. Knowing what you don't know is the first hint to really expanding your knowledge into non-obvious areas.
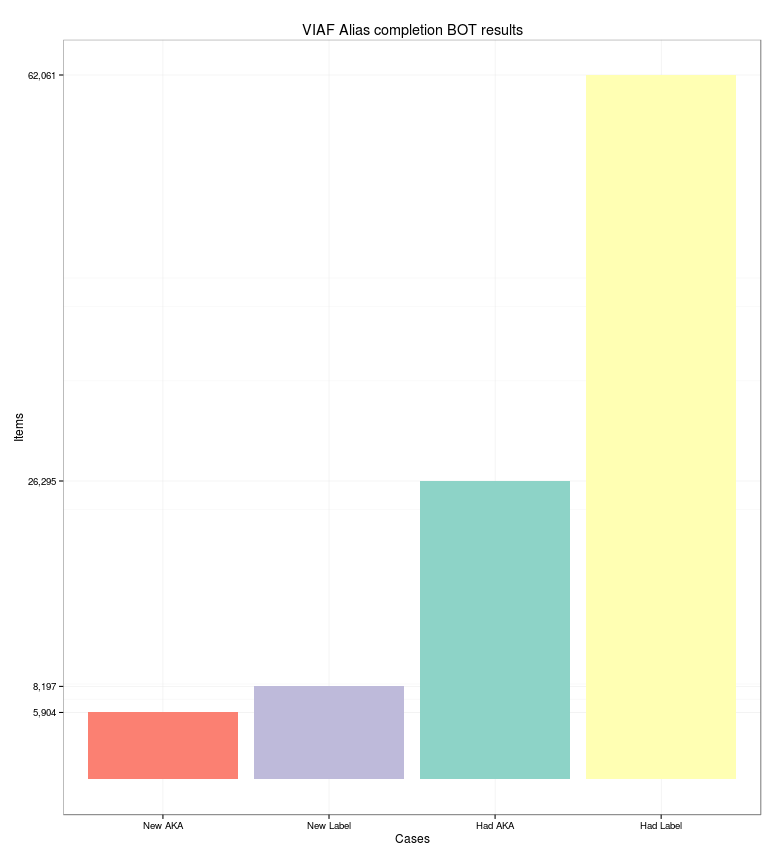
I tried to automate solving part of this problem. As I connect over 400,000 Wikidata items with their VIAF IDs, and VIAF has information about alternate names in different languages, there was some promise. For each item with an associated VIAF ID I found the potential alternative name. Then I used python to determine the probable language of string of text. If the alternate name was in a language that didn't already have a Wikidata label or alias, I checked Levenshtein distance of the label and alias versus the alternate name. If it was less that 65% similar - a threshold I determined by training a Bayesian filter - then I would write that label or alias. Here are the results: new AKA means that an alias was added, new label the same, had AKA means that the alias was available but greater than 65% similar, and likewise a label could be too similar.
Remember also to see my post about finding the label in every language for each language . Soon with babel, we might have label completion.