Against the Grain: Influencing Factors of Opinion Change in Wikipedia’s Article for Deletion Process
By max, Mon 04 January 2016, in category Research-notes
By max, Mon 04 January 2016, in category Research-notes
This is my final project from my Machine Learning course this past semester. My collaborators and I attempted to find out when, and why users at English Wikipedia's article for deletion forum, voted against their tendencies. That is, what makes an "deletionist" vote "keep" and when an "inclusionist" votes "delete"? In the end we found that basic machine learning techniques could not perform much better than random, but the intelligence that did emerge came from using information about group herding behaviour, and appeals to the local bureaucratic process.
On 1 November 2015, English Wikipedia hit 5,000,000 articles; but while article creation is much celebrated, deleting an article is a lesser known process. Article for Deletion (AfD) is the forum where users discuss, make arguments about and and vote on articles’ inclusion in Wikipedia. A final decision is made by a more experienced user, based on the “consensus” of the debate. Over the years AfD has become a highly cultural process which has been likened to a playground game where children gather piles of leaves and are then judged for their raking ability (Baker).
Indeed, there are two groups at AfD that have statistically significant homogeneous voting patterns - the [inclusionists] and [deletionists] (Taborelli and Ciampaglia). Those groups argue sometimes over whether an article is encyclopedic in general, but also over whether an article fits Wikipedia’s unique policies (Geiger and Ford). Corroborating this Schneider et al. found that “acceptable arguments [at AfD] demonstrate knowledge of policies and community values”.
With the understanding that the large-scale dynamics at AfD are creating two camps of voters, and set of acceptable arguments, we ask what’s happening when users change their minds?
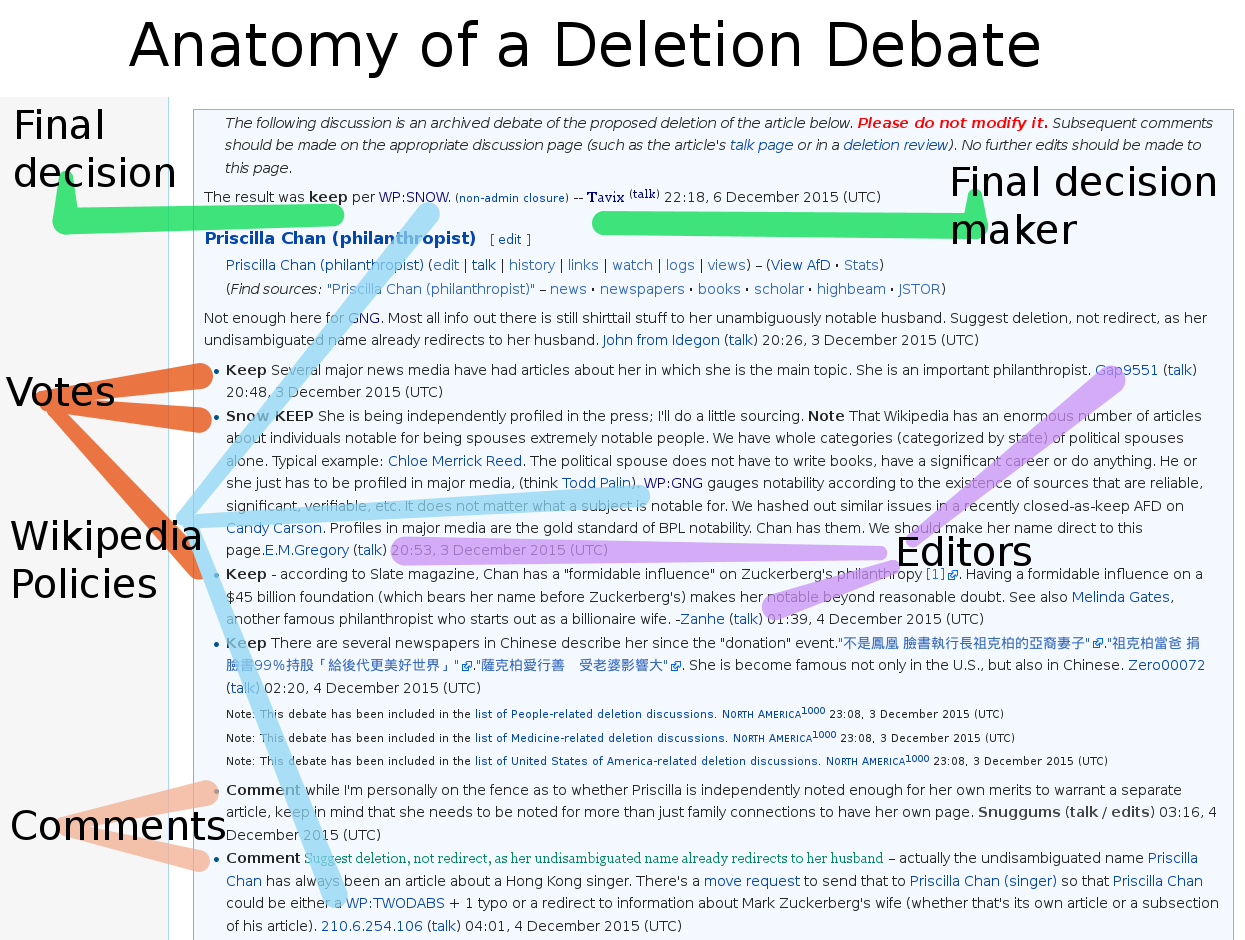 Figure 1: Anatomy of a deletion debate.
Figure 1: Anatomy of a deletion debate.
[RQ: Can we predict when people will vote against their tendencies at AfD, and what factors are involved?]
Methodologies of computer mediated group decision has been studied for a long time. A decision-making group can benefit from pooling member’s information ([Stasser and William]). It can be viewed as a dynamic process that people make persuasions via information changes and rational arguments ([Herrera and Herrera-Viedma]). Therefore, we borrowed a well studied consensus model (see Appendix Figure 3), which uses the current consensus stage and the individual’s distance to social opinions to inform feature extraction from our collected dataset.
Our data comes from publicly accessible historical Wikipedia pages from 2005 to 2011, collected by Prof. Haiyi Zhu. It contains records of 23996112 votes in [363,201] deletion discussions between 81,112 editors. Appendix Figure 4 (a) is the distribution on number of participants versus the voting counts for delete and keep respectively. In order to get a clear signal we excluded the voters who participated less than 100 times in the AFD discussion, in which case 1,237,140 voting records remain, with [13,225 ][editors on ][363,104 articles]. As for the filtered records, a voter’s behavior is examined after their initial 100[ votes. Appendix ][Figure 4(b)][ is the distribution on number of participants versus the voting counts for delete and keep respectively after filtering. Through this operation, the population sample falls into a smoother normal distribution. We believe the processed sample is more suitable for analysis because it represents that an equilibrium stage is reached for each voter as we assumed. ]
In preprocessing, we computed 1578 features for modeling. The features fall into two categories, 12 are descriptive features about the general discussion, like how conversation span, and number of participants (see Appendix Table 2 for complete details). The remaining features are the existence of a Wikipedia policy occurring in the discussion before the editor writes their comment. A Wikipedia Policy is a community practice codified into a Wiki page that is in a special namespace (whose name is the “Wikipedia” namespace). We filtered these policies out by searching for all links in the discussion text and then filtering on that special namespace. We then performed stemming, and redirect following, so that [Wikipedia:Notability (People)]. [Wikipedia:Notability (People)#Additional criteria], and [WP:BIO] all are aggregated as the same policy. Since we found more than 1500 mentioned policies, but very few mentioned in any comment, we converted our data in a CSR-sparse matrix, otherwise our data did not fit into 8gb of memory.
As for our target variable, is [vote likelihood], the probability[2] that an editor would make the current vote, based on their voting history. If a editor votes keep and their voting history is 75 keep / 25 delete, their [vote likelihood is 0.75].
[R][egression]
The studied target is the voting likelihood , which is a continuous variable, and could be influenced by the other features stated above. Therefore, linear regression method is used to map all other features to the voting likelihood. The other features are linearly combined to predict the voting likelihood.
The next method we implemented is the logistic regression. Since we extracted the voters included in the data set participated more than 100 times, their behavior is considered stable based on Figure 4. Therefore, the two different classes that are split by 0.5 can be considered deletionists and inclusionists. The l2 norm is used to compute the penalty while the tolerance is 0.0001.
[Classification]
Since the voting likelihood is a continuous variable, in order to perform classification we split them into two different classes giving the threshold as 0.5.The class prior distributions is approximately 64% voting with history (vote likelihood > 0.5) 36% voting against history (vote likelihood ≤ 0.5). Therefore, the following classification error rates should be compared with the 36% baseline a random classifier would perform.
[Adaboost]
The adaboost classifier is used where each base tree has 2 layers with a total of 500 trees. The learning rate is set to be 1. After calibration in Figure 3, we found the lower the learning rate, the lower the error rate.
[Gradient Boost]
We decided to run on 50% subsample of the total data for training since the error rate does not change significantly. Each base tree is also a 2 layers with a total of 500 trees. The learning rate is set to be 1.
We decided to execute random forest in order to conduct a feature selection process to show which were the most important features. Our forest size was 500 trees, each of depth 2, and selecting from 20 random features. We conducted this exercise three times to determine, how stable our data was under this process.
The results of the linear regression prediction is shown in Figure 4. The increasing black line is the theoretical line while the blue dots are the actual predicted value. As seen in the figure, linear regression’s result indicated nearly no predictive power over the entire data sets. Therefore, we decided to change the continuous variable regression problem into a binary class classification problem, whereas the different methods and results are shown below:
Table: Classification error rate and performance speed on Dell E7250 laptop.
[Error Rate] [Performance (seconds)]
[Logistic Regression] [34.3%] [120] [Adaboost] [32.6%] [180] [Gradient Boost] [32.5%] [30] [Random Forest] [33.12%] [180]
Based on the class priors, a random guessing algorithm’s error rate will be 36%. Therefore, we use that number to evaluate our approaches. The best prediction according to the tables is 32% error rate which is only slightly better than random. The rest algorithms dwell around 36% error rate. This means that among all the features, none of them have significant predictive power to predict the changes of voters’ voting behavior. Logistic regression method produces 0.05% training error rate while the test error rate is nearly 36%. We suspect this behavior is a result of overfitting the datasets.
Although the overall predictive power is low, from random forest method, we are still able to recover the baseline test-error, and extract the top important features that act as a weak learners.
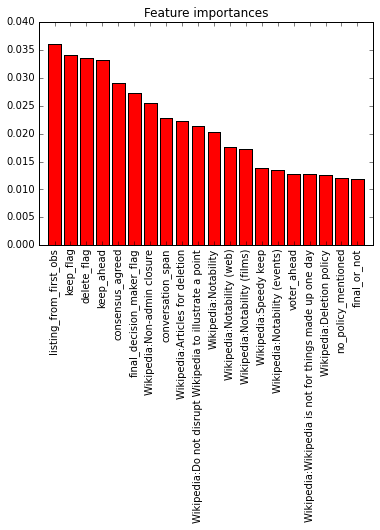 Figure 2: Top 20 most important features from Random Forest.
Figure 2: Top 20 most important features from Random Forest.
We ran our random forest model 3 times which had a consistent error rate at 36.4%. Running the algorithm 3 times did produce some jitter of the top 20 important features, but some features appeared consistently between runs (see table 1). We find that many of our non-policy features were consistently important in prediction.
In particular many temporal features were important, for instance that [conversation span] is important means that people change their opinions change more due to more conversation. Additionally [listing from first observation ]is important so conversation happening at later dates have are less likely to have editors changing their minds.
Other important features show “herding” dynamics as was found in (Taborelli and Ciampaglia). All of [voters ahead,] [keep ahead. ]and [consensus agreed] are important and this can be interpreted as that many people voting before will influence a voter to vote against their tendency. Specifically [keep ahead] means that if many people vote keep beforehand, a deletionist is likely to vote keep against their tendency. [Consensus agreed ]means that a user voted in the same direction as the final decision, so this feature being important quite explicitly shows herding mentality.
In terms of policies that were consistently important we find many self-referential policies, that illustrate the importance of internal process. Firstly navel-gazing policies such as [Wikipedia:Articles for deletion, Wikipedia:Deletion process, Wikipedia:Do not disrupt Wikipedia to illustrate a point ]and [Wikipedia:Non-admin ][closure,] show that editors seeing appeals of AfD process will likely vote against their tendencies. We can call this the [policy wonk ]effect, and it has been shown before in Schneider et al. “Newcomers are particularly likely to use certain common, but problematic, arguments, which are enshrined in policy and in essays such as Arguments to Avoid.”
Other features that showed important influence were notability guidelines:[ Wikipedia:Notability ][and it’s cousins],[ ]and[ Wikipedia:Biographies of living persons. ]Previous research has shown that the [notability ]policies in specific are being increasingly cited at AfD (Lam and Reidl). Biography of Living persons is an especially instructive case, because these biographies have to be exceptionally conservative compared to Wikipedia’s regular standard due to United States defamation laws and legal liability of the Wikimedia Foundation. Therefore that people would change their standard voting behaviour in this sensitive area is unsurprising.
We only used the 100 votes or more for analysis and the converting threshold is set as 0.5. Yet this does not guarantee an absolute decision shift, for instance an only 49% likely vote. A better algorithm for likelihood calculation can be adopted. For example, we can declare a voter’s equilibrium stage is reached once his or her voting likelihood changes restricts in a small changing range for N consecutive votes rather than a fixed number.
Psychological effects in group discussion is not quantifiable in our model. One missing impacting factor is the choice supportive bias of individuals. It states that there [is the tendency to retroactively ascribe positive attributes to an option one prefered. For example, when a person has preference on A over B, they are likely to downplay the faults of option A while amplifying those of option B.] Another limitation is the group bias, where irrational actions that is forbidden by an individual will be taken by when he/her is in a group.Yet, our current data does not have information to measure these effects. Since many temporal features seemed to be important, it would be good to investigate time-series based learning, as well.
Schneider, Jodi et al. “Arguments About Deletion: How Experience Improves the Acceptability of Arguments in Ad-Hoc Online Task Groups.” Proceedings of the 2013 Conference on Computer Supported Cooperative Work. New York, NY, USA: ACM, 2013. 1069–1080. ACM Digital Library. Web. 12 Dec. 2015. CSCW ’13.
Baker, Nicholson. “The Charms of Wikipedia.” The New York Review of Books 20 Mar. 2008. The New York Review of Books. Web. 7 Oct. 2015.
Taraborelli, D., and G.L. Ciampaglia. “Beyond Notability. Collective Deliberation on Content Inclusion in Wikipedia.” 2010 Fourth IEEE International Conference on Self-Adaptive and Self-Organizing Systems Workshop (SASOW). N.p., 2010. 122–125. IEEE Xplore. Web.
Geiger, R. Stuart, and Heather Ford. “Participation in Wikipedia’s Article Deletion Processes.” Proceedings of the 7th International Symposium on Wikis and Open Collaboration. New York, NY, USA: ACM, 2011. 201–202. ACM Digital Library. Web. 7 Oct. 2015. WikiSym ’11.
Lam, Shyong (tony K., and John Riedl. Is Wikipedia Growing a Longer Tail? N.p. Print.
[Stasser, Garold, and William Titus. "Pooling of unshared information in group decision making: Biased information sampling during discussion." ][Journal of personality and social psychology]{.c2 .c15}[ 48, no. 6 (1985): 1467.]
[H][errera, F., and E. Herrera-Viedma. "A model of consensus in group decision making under linguistic assessments." ][Fuzzy sets and Systems]{.c2 .c15}[ 78, no. 1 (1996): 73-87.]
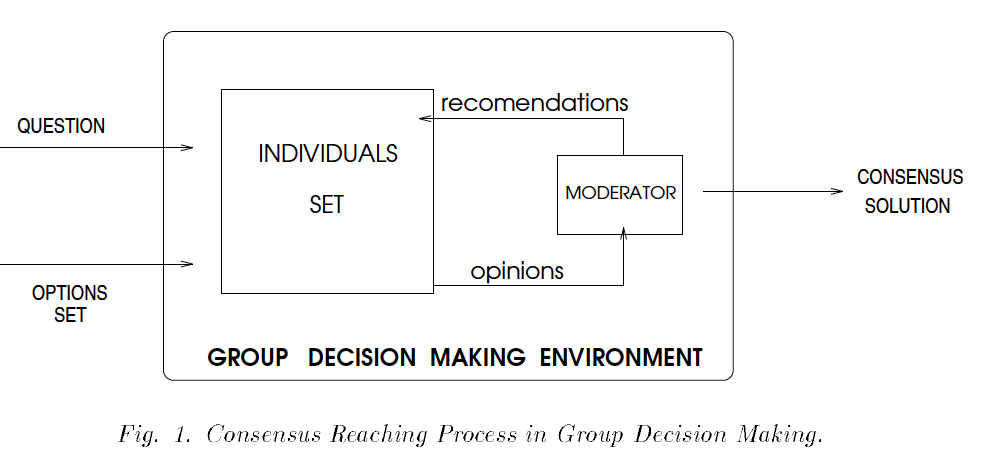 Appendix Fig 1. Group Decision Making
Appendix Fig 1. Group Decision Making
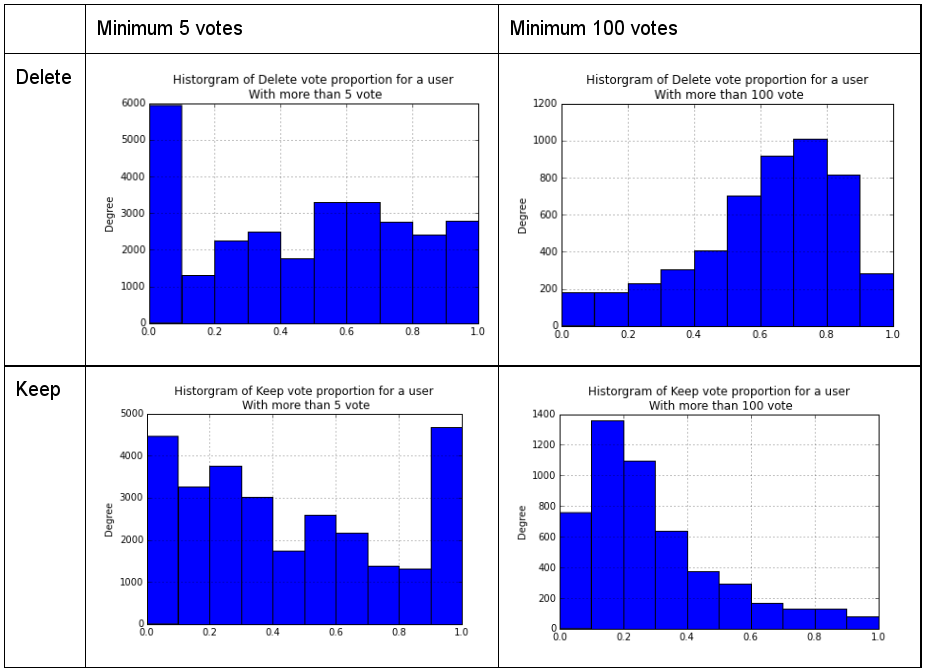 Figure 2. Histograms of Users' "Delete" and "Keep" Frequencies, by Minimum (a) 5, (b) 100 votes.
Figure 2. Histograms of Users' "Delete" and "Keep" Frequencies, by Minimum (a) 5, (b) 100 votes.
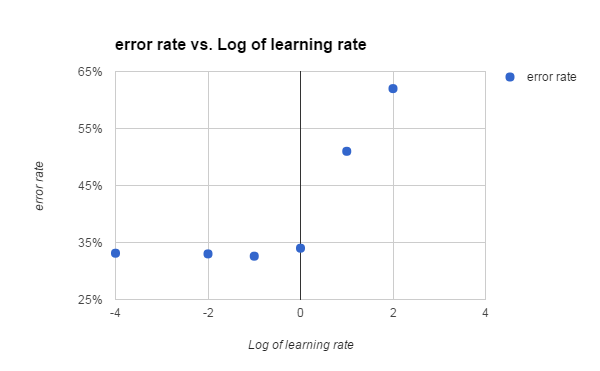 Figure 3. Log of learning rate vs error for adaboost classifier.
Figure 3. Log of learning rate vs error for adaboost classifier.
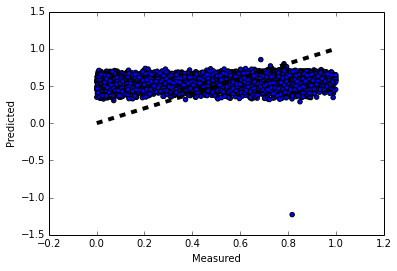 Figure 4: The linear regression prediction for the voting likelihood (The black line is the theoretical fit).[/caption]
Figure 4: The linear regression prediction for the voting likelihood (The black line is the theoretical fit).[/caption]
Table 1. Top 20 features from Random Forest over 3 runs.
[Features appearing in all Random Forest Runs] [Features appearing in 2 of 3 Random Forest Runs]
[consensus_agreed] [Wikipedia:Arguments to avoid on discussion pages]
[conversation_span] [Wikipedia:Article size]
[delete_flag] [Wikipedia:Deletion policy]
[final_or_not] [Wikipedia:Esperanza]
[keep_ahead] [Wikipedia:Notability (events)]
[keep_flag] [Wikipedia:Notability (web)]
[listing_from_first_obs] [Wikipedia:VAIN]
[no_policy_mentioned] [Wikipedia:Verifiability]
[voter_ahead] [Wikipedia:Wikipedia is not for things made up one day]
[Wikipedia:Articles for deletion]
[Wikipedia:Biographies of living persons]
[Wikipedia:Deletion process]
[Wikipedia:Do not disrupt Wikipedia to illustrate a point]
[Wikipedia:Non-admin closure]
[Wikipedia:Notability]
Table 2. Descriptive Features
+-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Feature] | [Description] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Time Influence (listing from first obs)] | [This variable is calculated by the difference between article’s listing days and] | | | | | | [the very first observation date within dataset, which is the 2005/12/07 for our experiment.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Conversatio Span] | [This indicates how long the deletion conversation last.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Participant Count] | [The total number of participants in the conversation] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Keep Flag] | [This variable identifies whether the final decision for the article is keep or not.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Delete Flag] | [This variable identifies whether the final decision for the article is delete or not.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Consensus Agreed] | [This variable indicates whether final decision matches the user’s vote.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Final decision maker flag] | [This variable indicates whether this editor is final decision.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Voters Ahead] | [This variable counts how many people have voted before the very person to write comment during the conversation.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Delete Ahead] | [This variable counts the number delete comment a voter exposed to before he/she writes a comment.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Keep Ahead] | [This variable counts the number keep comment a voter exposed to before] | | | | | | [he/she writes a comment.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+ | [Mentioned Policies] | [From the argument content, we extracted links to Wikipedia policy pages.] | +-------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------+